
Machine Learning Explained: Model Types Explained
This post explores different types of machine learning models used for different types of cases and the majority of common machine learning models used in practice.
The Machine Learning Explained: Introduction post explains the two main types of machine learning. All machine learning models are categorised as either supervised or unsupervised.
Supervised Learning Models
Supervised learning involves learning a function that maps an input to an output based on example input-output pairs. For example, if a dataset had two variables, age (input) and height (output), a supervised learning model could be implemented to predict the height of a person based on their age. An intelligent correlation analysis can lead to a greater understanding of the data. It is useful to use correlation alongside regression as it can more easily present the relationship between two varibles.
Supervised learning models fall in two sub-categories: regression and classification.
Correlation
Correlation is a measure of how strongly one variable depends on another. In terms of ML, this is how features correspond with the output.
Regression
Regression is typically the next step up after correlation and understanding the data better. In regression models, the output is continuous and it finds the causal relationship between variables X and Y allows for accurate prediction of the Y value for each X value.
Linear Regression
Linear regression finds a line that best fits the data as shown in the image below. Extensions of linear regression include multiple linear regression and polynomial regression.

Decision Tree
Decision trees are popular models used in research, planning and mahcine learning. each decision is called a node, and the more nodes there are, the more accurate the decision tree will be (generally). The last nodes of the decision tree, where a decision is made, are called the leaves of the tree. Decision trees are intuitive and easy to build but fall short when it comes to accuracy.
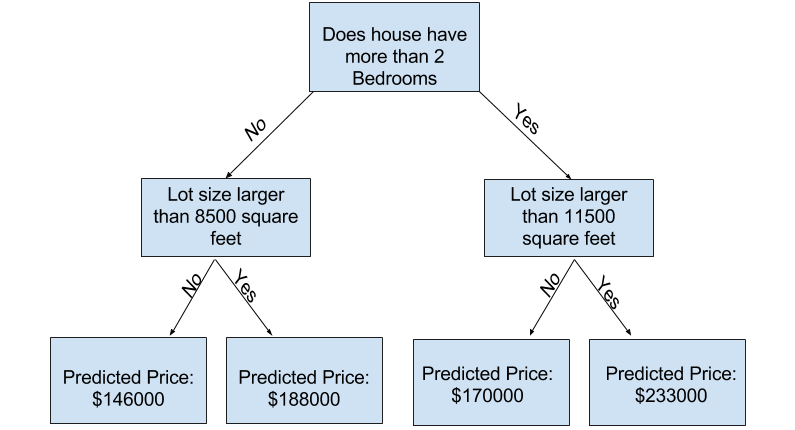 In the image above, each box is a node and te final set of boxes are the leaves.
In the image above, each box is a node and te final set of boxes are the leaves.
Random Forest
Random forests are an ensemble learning technique that build off of decision trees. Ensemble learning is the process by which multiple models, such as classifiers or regression models, are generated and combined to solve a particular problem. Random forests involve creating multiple decision trees using bootstrapped datasets (resampling) of the original data and randomly selecting a subset of variables at each step of the decision tree. The model then selects the mode of all the predicionts of each decision tree and the most frequent model is chosem. This relies on a “majority wins” model and reduces the risk of error from an individual tree.

In the example abode, if a single decision tree was created (third one), it would predict 0, but by relying on the mode (most frequent occurence) of all four decision trees, the predicted value would be 1. This is the power of random forests.
Neural Network
A neural network is essentially a network of mathematical equations. It takes one or more input variables and results in one or more output variables by going thorugh the entire network of equations. This post explains neural networks used in deep learning and how they are structured.
Classification
Classification is another type of supervised learning method in which the output is discrete (and finite). Classification is a process of categorising a given set of data into classes. The process starts with predicting the class of given data points. The classes are often referred to as target, label or categories. Below are some of the most common types of classification models.
Logistic Regression
Logistic regression is similar to linear regression but is used to model the probability of a finite number of outcomes, typically two. There are many reasons why logistic regression is used over linear regression when modelling probabilities of outcomes, which include non-negative values, better results (unbiased), and lower variances. To summarise, a logistic equation is created in such a way that the outpt values can only be between 0 and 1.

The above image shows typical logistic regression, which is clearly between 0 and 1.
Support Vector Machine
A support vector machine (SVM) is a supervised classification technique that can get pretty complex. If there are two classes of data, a SVM will find a hyperplane or a boundary between the two classes of data that maximised the margin between the two classes (shown in the image below). There are many planes that can separate the two classes, but only one plane can maximise the margin/distance between the classes.

This article written by Savan Patel goes into detail on the theory behind SVMs and how complicated they can be (and he definitely explains it better!) and it’s a great read.
Naive Bayes
Naive Bayes is another really popular classifier used in machine learning. The idea behind it is devien by Bayes Theorem, which any mathematician or statistician must be familiar with. The theorem is:

This essentially translates to “what is the probability of event y occuring given event X?”, where y is the output variable. For Naive Bayes, an assumption that variables are independent given the class is made, so it becomes (denominator removed):

| So, P(y | X) is proportional to the right-hand side: |

Therefore, the goal is to find the class y with the maximum proportional probability.
Unsupervised Learning
Unlike supervised learning, unsupervised learning is used to draw inferences and find patterns from input data wihtout references to labelled outcomes. Two main methods used in unsupervised learning include clustering and dimensionality reduction.
Clustering
Clustering involves the grouping or clustering of data points. The aim is to segregate groups with similar traits for tasks such as customer segmentation, fraud detection, etc.. Common clustering techniques include the following:
K-Means
K-means finds groups in data, with the number of groups represented by the variable “K”. The algorithm works iteratively to assign each data point to one of K groups based on the features that are provided. Data points are clusetered based on feature similarity. The results of K-means clustering algorithm are:
- Centroids of the K-clusters, which can be used to label new data
- Labels for training data (each dta point is assigned to a single cluster). Clustering allows for analysis of groups that have formed organically, rather than defining groups before looking at the data. Each centroid of a cluster is a collection of feature values which define the resulting groups. Examining the centroid feature weights can be used to qualitatively interpret what kind of group each cluster represents.

The image above shows how K-means finds clusters in data.
Heirarchical Clustering
Heirarchical clusering is an algorithm similar to the K-means, but outputs structure that is more informative than the unstructured set of flat clusters returned in the form of a heirarchy. Thus, it is easier to decide on the number of cluseters by looking at the dendrogram. The image shown below represents a dendrogram that shows the clustering of letters A-F.

Density-Based Clustering
Density-based clustering is a clustering method that identifies distinctive groups/clusters in the data by detecting areas where points are concentrated (high density) and where they are separated by areas that are empty (low density).

Dimensionality Reduction
Dimensionality reduction is the process of reducting the number of random variables (features) under consideration by obtaining a set of principle variables. In simpler terms, it is the process of reducting the dimension of the feature set, or just reducing the number of features. Most dimensionality reduction techniques can be categorised as either feature elimination (removing a feature) or feature extraction (identifying important features).
Principal Component Analysis (PCA)
Principal component analysis (or PCA for short) is a popular dimensionality reduction method. PCA is a statistical procedure that allows the summarisation of information content in large data tables by means of a smaller set of “summary indices” that can be visualised/analysed more easily. A simple example is projecting higher dimensional data (e.g. 3 dimensions) to a smaller space (2 dimensions). This results in lower dimension of data (2 dimensions instead of 3 dimensions) while keeping all original variables in the model. the method goes as follows: 1. The aim is to standardise the range of the continuous variables so that each one of them contributes equally to the analysis. Once this is done, all the variables will be transformed to the same scale. 2. Understand how the variables of the input data set are varying from the mean with respect to each other (look for any relationships between the variables). This is important because variables can be highly correlated in such a way that they contain redundant information. In order to identify these correlations, the covariance matrix can be computed. If the sigh of the covariance is positive, the two variables increase or decrease together (correlated), whereas, if the sign is negative, then one variable increases as the other decreases (inversely correlated). 3. Eigenvectors and eigenvalues are computed from the covariance matrix in other to determine the principal components of the data. Principal components are new variables that are constructed as linear combinations or mixture of the initial variables. These combinations are done in such a way that the new variables (i.e., principal components) are uncorrelated and most of the information within the initial variables is squeezed or compressed into the first components.

Conclusion
There is clearly a ton of complexity when focusing on any particular model, but this post should provide a fundamental understanding of how each machine learning algorithm works and the possible use cases for it.
Leave a Comment